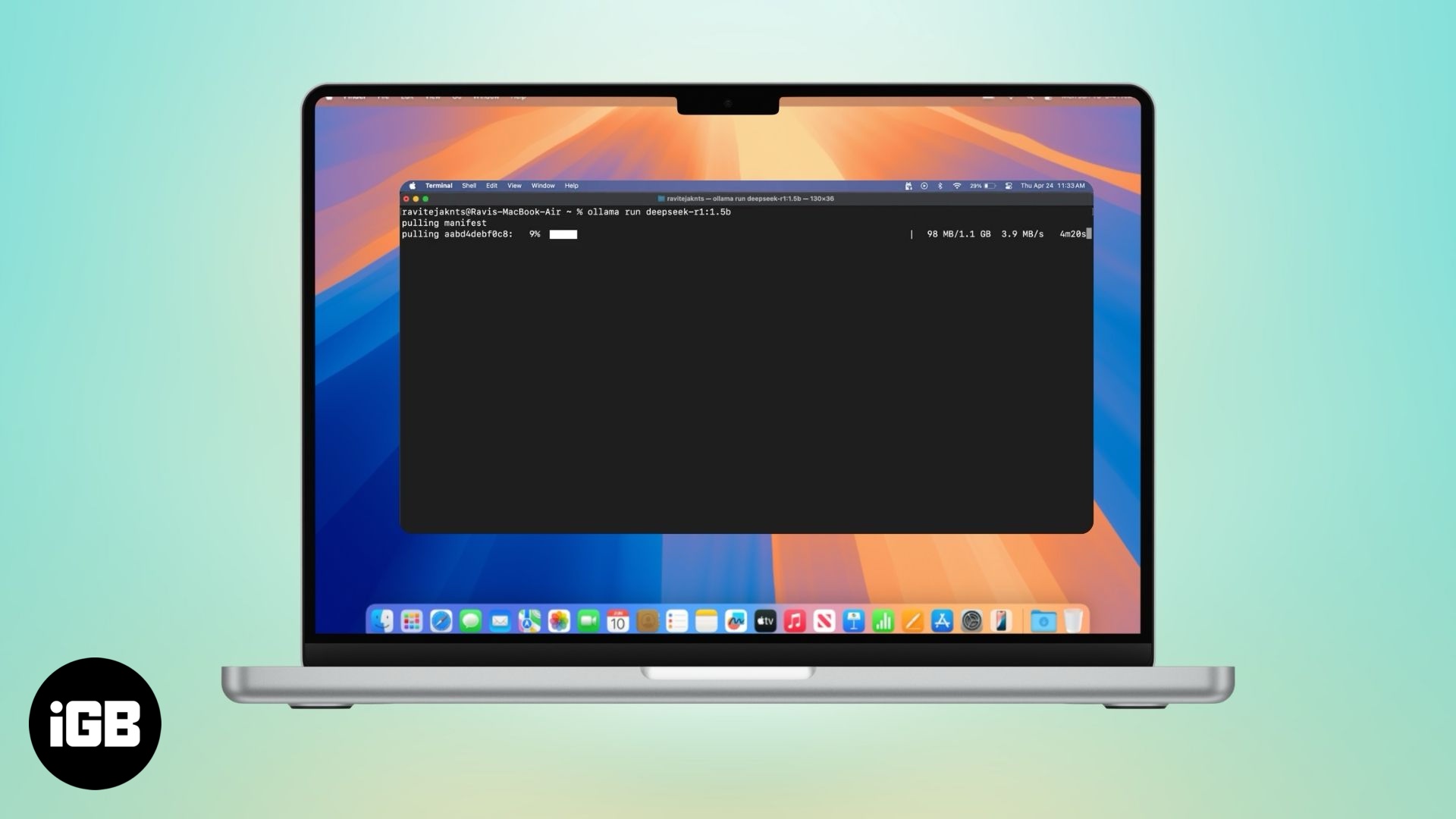
Czy zastanawiałeś się kiedyś, czy możesz uruchomić coś takiego jak ChatGPT lokalnie na swoim Macu, bez konieczności korzystania z Internetu? Przy odrobinie konfiguracji naprawdę jest to możliwe. To też za darmo. Niezależnie od tego, czy chcesz zachować prywatność czatów, czy po prostu chcesz mieć dostęp do sztucznej inteligencji w trybie offline, oto sposób, w jaki możesz uruchamiać potężne modele wielojęzyczne lokalnie na komputerze Mac.
#tytuł_obrazu
Czego potrzebujesz, aby uruchomić LLM lokalnie na komputerze Mac?
Zanim zagłębimy się w konfigurację i sprawdzimy konfigurację, oto czego będziesz potrzebować:
Będziemy korzystać z bezpłatnego narzędzia o nazwieByć, który umożliwia pobieranie i uruchamianie LLM lokalnie za pomocą zaledwie kilku poleceń. Oto jak zacząć:
Zobacz także:Jak uruchomić Eksplorator plików jako administrator w systemie Windows 11
Krok 1: Zainstaluj Homebrew (pomiń, jeśli jest już zainstalowany)
Homebrew to menedżer pakietów dla systemu macOS, który pomaga instalować aplikacje z aplikacji Terminal. Jeśli masz już zainstalowany Homebrew na komputerze Mac, możesz pominąć ten krok. Ale jeśli nie, oto jak możesz go zainstalować:
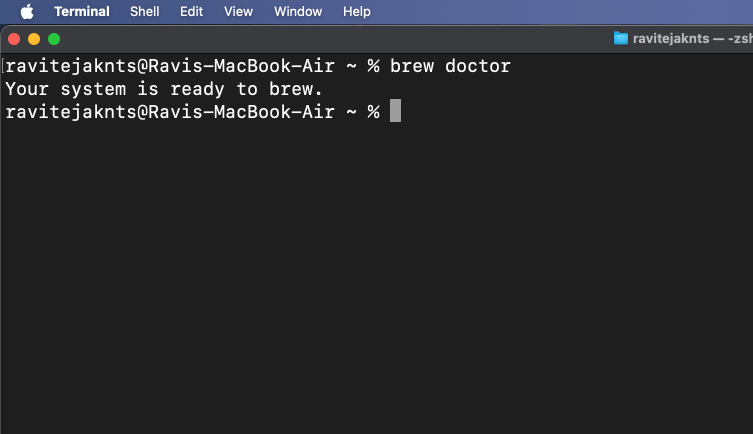
/bin/bash -c "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/HEAD/install.sh)"brew doctor
Jeśli zobaczysz komunikat „Twój system jest gotowy do zaparzenia”, możesz zaczynać.
Jeśli masz jakiekolwiek problemy lub chcesz uzyskać bardziej szczegółowy proces krok po kroku, zapoznaj się z naszym przewodnikiem na temat instalacji Homebrew na komputerze Mac.
Krok 2: Zainstaluj i uruchom Ollamę
Teraz, gdy Homebrew jest zainstalowany i gotowy do użycia na komputerze Mac, zainstalujmy Ollamę:
brew install ollamaollama serve
Pozostaw to okno otwarte lub zminimalizuj je. To polecenie sprawia, że Ollama działa w tle.
Alternatywnie pobierz plikAplikacja Ollamai zainstaluj ją jak każdą zwykłą aplikację na Maca. Po zakończeniu otwórz aplikację i pozwól jej działać w tle.
Krok 3: Pobierz i uruchom model
Ollama zapewnia dostęp do popularnych LLM, takich jak DeepSeek, Meta's Llama, Mistral, Gemma i innych. Oto jak możesz wybrać i uruchomić jeden z nich:
Jeśli wybierzesz duży model, spodziewaj się pewnych opóźnień – w końcu cały model działa lokalnie na Twoim MacBooku. Mniejsze modele reagują szybciej, ale mogą mieć problemy z dokładnością, szczególnie w przypadku zadań matematycznych i logicznych. Pamiętaj też, że ponieważ te modele nie mają dostępu do Internetu, nie mogą pobierać informacji w czasie rzeczywistym.
To powiedziawszy, do sprawdzania gramatyki, pisania e-maili lub burzy mózgów sprawdzają się znakomicie. Często korzystałem z DeepSeek-R1 na moim MacBooku z konfiguracją interfejsu internetowego, która pozwala mi także przesyłać obrazy i wklejać fragmenty kodu. Chociaż jego odpowiedzi — a zwłaszcza umiejętności kodowania — nie są tak ostre, jak modele z najwyższej półki, takie jak ChatGPT czy DeepSeek 671B, nadal większość codziennych zadań można wykonać bez konieczności korzystania z Internetu.
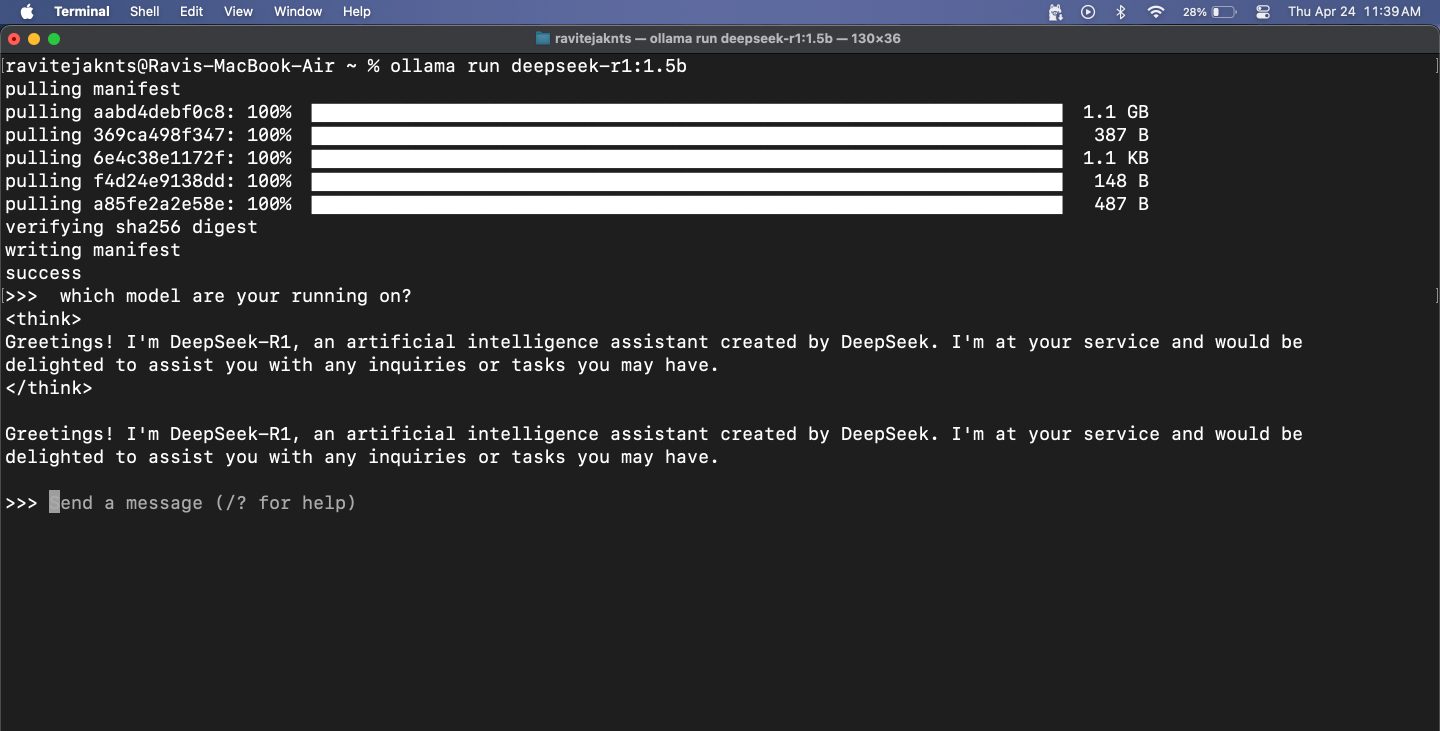
Krok 4: Porozmawiaj z modelką w Terminalu
Po uruchomieniu modelu możesz po prostu wpisać wiadomość i nacisnąćPowrót. Model odpowie tuż poniżej.
Aby zakończyć sesję, naciśnijKontrola+Dna klawiaturze. Jeśli chcesz ponownie rozpocząć rozmowę, użyj tego samegoollama run [model-name]rozkaz. Ponieważ model jest już pobrany, uruchomi się natychmiast.
Krok 5: Przeglądaj i zarządzaj zainstalowanymi modelami
Aby sprawdzić, które modele są aktualnie pobrane, uruchom:
ollama list
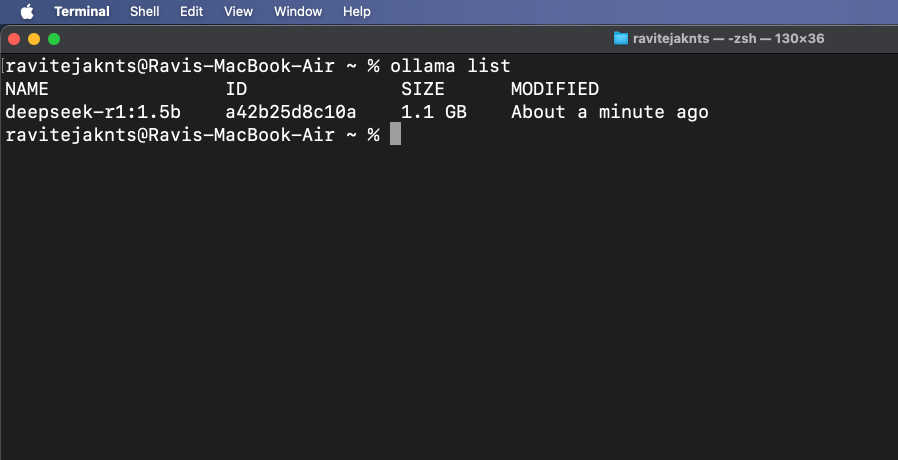
Aby usunąć model, którego już nie potrzebujesz, użyj:
ollama rm [model-name]Bonus: Użyj Ollama z interfejsem użytkownika w Internecie
Chociaż Ollama działa w terminalu, uruchamia również lokalną usługę API pod adresem https://localhost:11434, umożliwiając połączenie go z interfejsem internetowym w celu wizualnej interakcji z modelami – podobnie jak przy użyciu chatbota. Jedną z popularnych opcji jest Open WebUI, który zapewnia przyjazny dla użytkownika interfejs oprócz podstawowej funkcjonalności Ollama. Zobaczmy, jak to skonfigurować.
Krok 1: Zainstaluj Dockera
Docker to narzędzie, które pozwala spakować program i wszystkie jego istotne elementy do przenośnego kontenera, dzięki czemu można go łatwo uruchomić na dowolnym urządzeniu. Wykorzystamy go do otwarcia interfejsu czatu internetowego dla Twojego modelu AI.
Jeśli Twój Mac jeszcze go nie ma, wykonaj poniższe kroki, aby zainstalować Docker:
docker --version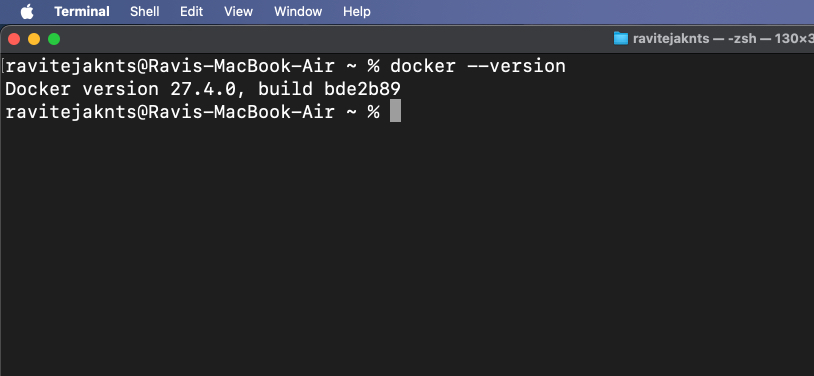
Jeśli polecenie zwróci numer wersji, oznacza to, że na komputerze Mac jest zainstalowany Docker.
Krok 2: Wyciągnij obraz Open WebUI
Open WebUI to proste narzędzie, które udostępnia okno czatu w przeglądarce. Wyciągnięcie obrazu oznacza po prostu pobranie plików potrzebnych do jego uruchomienia.
Aby to zrobić, przejdź doTerminalaplikacja i wpisz:
docker pull ghcr.io/open-webui/open-webui:mainSpowoduje to pobranie niezbędnych plików interfejsu.
Krok 3: Uruchom kontener Docker i otwórz WebUI
Teraz czas uruchomić Open WebUI za pomocą Dockera. Zobaczysz przejrzysty interfejs, w którym możesz rozmawiać ze swoją sztuczną inteligencją – nie potrzebujesz terminala. Oto, co musisz zrobić:
docker run -d -p 9783:8080 -v open-webui:/app/backend/data --name open-webui ghcr.io/open-webui/open-webui:main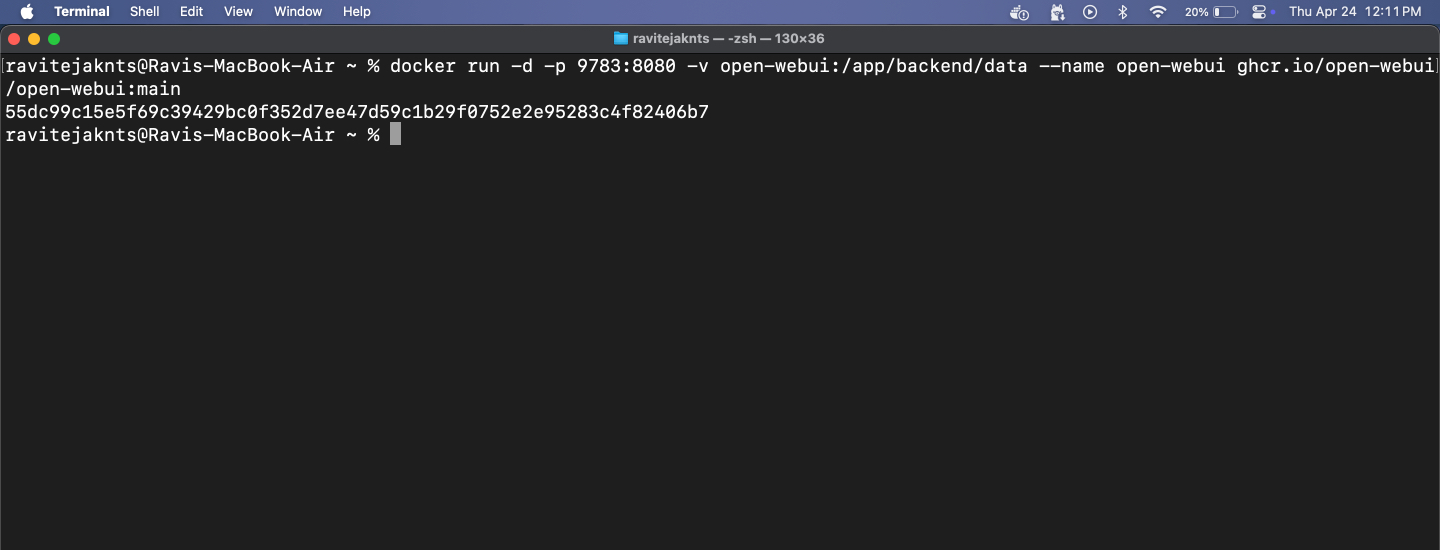
https://localhost:9783/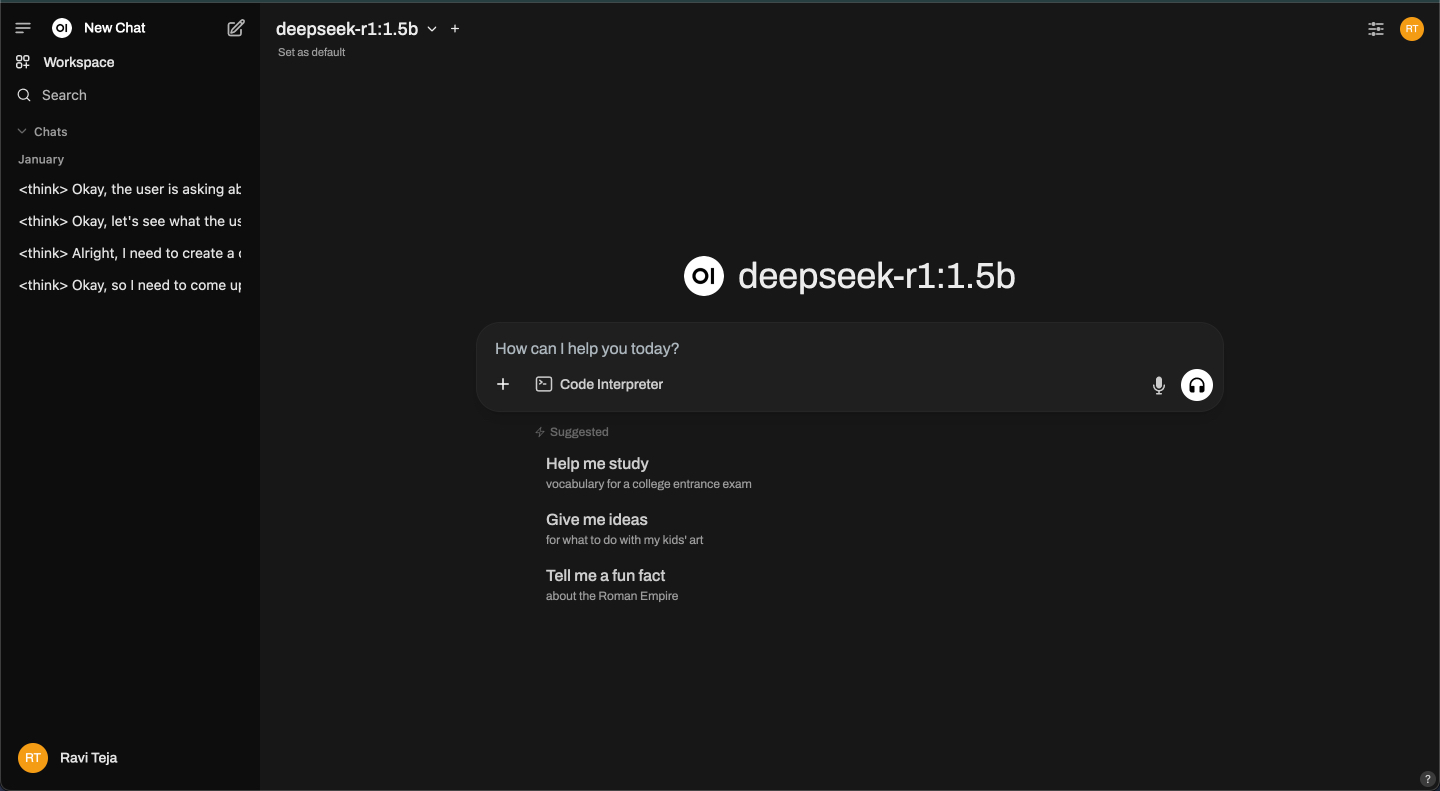
Stąd możesz rozmawiać z dowolnym zainstalowanym modelem w przejrzystym, przyjaznym dla użytkownika interfejsie przeglądarki. Ten krok jest opcjonalny, ale zapewnia płynniejszą obsługę czatu bez korzystania z terminala.
Twój Mac, Twoja sztuczna inteligencja: bez serwerów i bez zobowiązań
To wszystko! W kilku krokach skonfigurujesz komputer Mac do uruchamiania potężnego modelu sztucznej inteligencji całkowicie offline. Po konfiguracji nie są potrzebne żadne konta, żadna chmura ani Internet. Niezależnie od tego, czy chcesz prowadzić prywatne rozmowy, generować lokalnie SMS-y, czy po prostu chcesz eksperymentować z LLM, Ollama sprawia, że jest to łatwe i dostępne – nawet jeśli nie jesteś programistą. Spróbuj!
Sprawdź także te pomocne przewodniki: