Firma Apple wprowadziła SlowFast-LLaVA-1.5, nową rodzinę wielkojęzycznych modeli wideo (Video-LLM), zaprojektowanych z myślą o wydajnym zrozumieniu długich formatów wideo. W swoim artykule badawczym Apple wyjaśnia, że większość istniejących dostawców LLM zajmujących się wideo boryka się z wysokimi kosztami obliczeniowymi i nadmiernym wykorzystaniem tokenów podczas analizowania rozszerzonej treści wideo, co ogranicza ich zdolność do skalowania. SlowFast-LLaVA-1.5 rozwiązuje ten problem, wprowadzając wydajną strukturę tokenów, która zmniejsza liczbę tokenów potrzebnych do reprezentowania wideo przy jednoczesnym zachowaniu dokładności.
Wydajność tokenów ma kluczowe znaczenie, ponieważ każda klatka w filmie musi zostać przekonwertowana na tokeny, zanim LLM będzie mógł ją przetworzyć. W przypadku długich filmów liczba tokenów szybko staje się niemożliwa do zarządzania, co zwiększa koszty i spowalnia wydajność. Podejście Apple kompresuje dane wideo, dzięki czemu wykorzystuje się mniej tokenów bez utraty ważnego kontekstu. Łącząc to z architekturą dwuścieżkową, w której „powolna” ścieżka oddaje długoterminowe wzorce, a „szybka” ścieżka koncentruje się na szczegółach krótkoterminowych, model może zrównoważyć zrozumienie i wydajność. Pozwala to śledzić zarówno nadrzędne wątki fabularne, jak i szczegółowe działania w dłuższych sekwencjach.
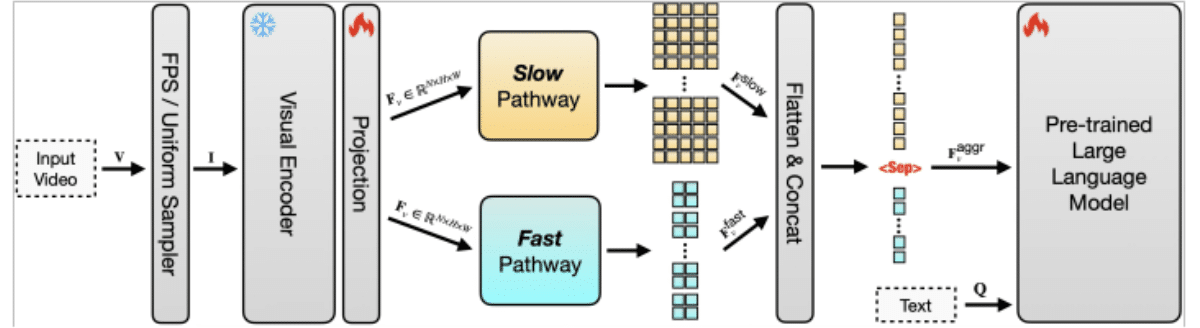
System jest również wysoce skalowalny, co oznacza, że można go rozbudować, aby obsługiwać znacznie dłuższe filmy i większe zbiory danych bez przytłaczania zasobów obliczeniowych. Tradycyjne modele stają się niepraktyczne wraz ze wzrostem długości wejściowej, ale konstrukcja Apple zapewnia, że skalowanie od krótkich klipów do wielogodzinnych nagrań pozostaje wykonalne. Dzięki temu SlowFast-LLaVA-1.5 nadaje się do zadań takich jak odpowiadanie na pytania wideo, wnioskowanie czasowe, podsumowywanie i wyszukiwanie treści w długich archiwach wideo.
W testach porównawczych Apple podaje, że model osiąga dobre wyniki w zestawach danych, takich jak Video-MME i LongVideoBench, wykazując zarówno lepszą wydajność, jak i zrozumienie w porównaniu z wcześniejszymi podejściami. W badaniu wprowadzono także wiele rozmiarów modeli, w tym wersje parametrów 1,5B, 7B i 13B, które są dostrojone zgodnie z instrukcjami tak, aby odpowiadały podpowiedziom języka naturalnego. Umożliwia to systemowi generowanie szczegółowych odpowiedzi na temat złożonych treści wideo, dzięki czemu można go wykorzystać do analizy filmów edukacyjnych, podsumowań spotkań i narzędzi ułatwień dostępu, które tworzą podpisy lub transkrypcje z możliwością przeszukiwania.
Przeczytaj więcej:TikTok umożliwia przesyłanie długich treści w formie 60-minutowych filmów
Apple podkreśla, że w wydajnym tokenie i skalowalnym projekcie chodzi nie tylko o nowatorstwo badawcze, ale o praktyczność. Obniżając wymagania obliczeniowe i zwiększając możliwości, model toruje drogę do integracji długoterminowej wiedzy wideo z produktami ze świata rzeczywistego. Ponieważ w rozrywce, edukacji i komunikacji zawodowej nadal dominuje wideo, zakrojona na szeroką skalę platforma wideo LLM firmy Apple stanowi znaczący krok w kierunku uczynienia zaawansowanej multimodalnej sztucznej inteligencji zarówno użyteczną, jak i dostępną.
Sprawdź cały dokumentTutaj.